Para quem ainda tem alguma dúvida sobre o curso “LAFF-On Programming for High Performance“, da Universidade do Texas na edX, o gráfico abaixo mostra o desempenho da CPU de meu notebook ao realizar uma operação de multiplicação de matrizes (C := AB + C), apenas alterando-se a ordem de execução de loops (discussão inicial da primeira semana do curso): as diferenças são incríveis!
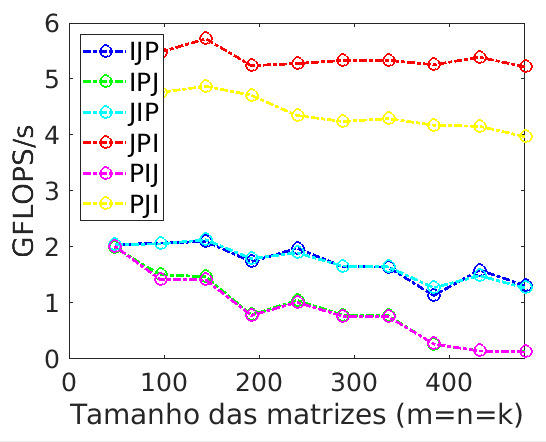
- Primeira lição do dia: até os algoritmos mais simples podem ser otimizados se soubermos apenas reordenar loops; e
- Segunda lição do dia: nem sempre o compilador (GCC) consegue otimizar o código da melhor forma, cabe a nós dar uma ajuda.
Se você se interessa por computação científica de alta performance, talvez esse curso seja interessante! Ainda dá tempo de acompanhar…